Kinds of data
The phenomena that provide the heuristic point of departure for a discipline are only its ultimate substrate, which is not itself processed by the scientist (though it may be by the practitioner). The data of a discipline are always representations of such phenomena. That is, they are essentially third-order entities by the ontology of naive realism. Thus, the ultimate substrate of linguistics is the total of actual linguistic activity occurring in the world. Linguistic data are recordings and representations of a set of such phenomena. Linguistic data may be classified by several parameters:
- By the criterion of whether the data have a historical (spatio-temporal) identity or are stripped of it by abstraction, they are primary vs. secondary data.
- Primary data are subdivided into processed data and raw data by the criterion of whether they are symbolically represented or not.
- Cross-classifying with the former distinction, primary data are also subdivided into original recordings and derived representations by the criterion of whether the representation directly reflects the ultimate substrate or is derived from another representation.
This categorization of linguistic data types is visualized in the following schema:
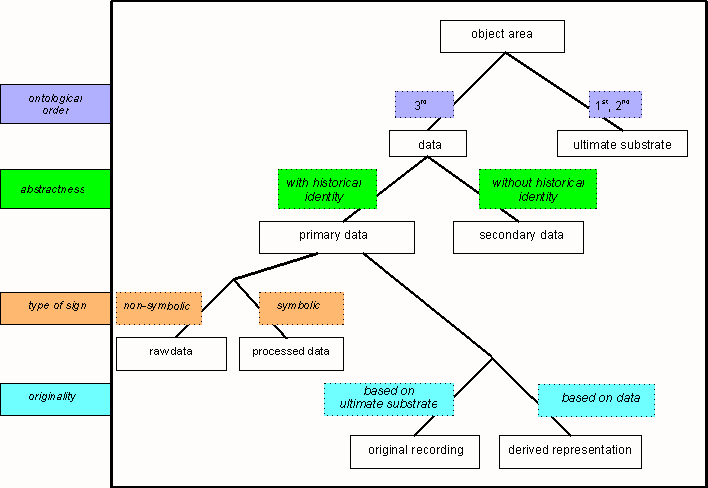 |
To give some examples:
- A video-recording of some communicative event is a piece of raw primary data in its original recording.
- A transcription of an audio-recording is a piece of processed primary data in a derived representation.
- The same goes for a copy of a written text in an electronic corpus, including annotations on it.
- Example sentences in a grammar or dictionary – assuming they are data at all – are secondary data.
For more discussion, s. Lehmann 2004[Data].