Grundbegriffe
Jede sprachliche Einheit E steht im Schnittpunkt zweier Arten von Relationen. Einerseits nimmt sie in der Kette eine bestimmte Position ein, an der statt ihrer andere sprachliche Einheiten (desselben Typs) stehen könnten. Zu diesen hat E paradigmatische Relationen. Andererseits stehen vor und nach E andere sprachliche Einheiten (desselben Typs). Zu diesen hat E syntagmatische Relationen.
Jeder der beiden Achsen entspricht eine fundamentale Operation der Sprachtätigkeit. Eine Einheit wird gemäß ihren paradigmatischen Relationen selektiert und gemäß ihren syntagmatischen Relationen mit anderen Einheiten kombiniert. Die paradigmatischen Relationen schaffen also sprachliche Klassen, die syntagmatischen Relationen schaffen Konstruktionen.
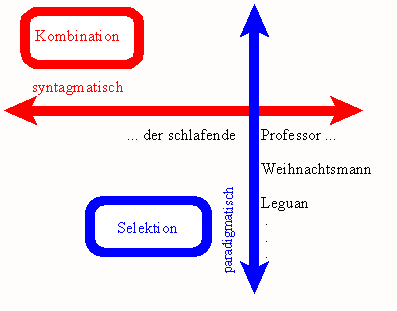
Das Gesagte gilt für alle sprachlichen Einheiten vom einzelnen Laut aufwärts bis zum Satz. Selektion und Kombination finden auf allen Ebenen gleichzeitig statt. Es ist also nicht so, daß der Sprecher zuerst Einheiten einer bestimmten Ebene (z.B. Morpheme) selektierte und sie dann zu einer Einheit der nächsthöheren Ebene (Wortform) kombinierte; sondern indem er diese Kombination vornimmt, selektiert er gleichzeitig diese nächstkomplexere Einheit anstelle von anderen Einheiten (Wortformen) derselben Ebene.
Der Kontext (i.e.S.) einer sprachlichen Einheit EEEE
In formaler Darstellung wird der Kontext von E
X __ Y
wo X und Y für die die Umgebung bildenden Einheiten bzw. deren Kategorien und der Unterstrich für die syntagmatische Position von E
| . | a. | hat __ gebissen |
| b. | [ hab- ]V.fin __ [ X ]V.part.perf |
.a ist also zu lesen: was unmittelbar nach hat und unmittelbar vor gebissen steht. Da kann man u.a. den Briefträger, mich, alle vorübergehenden Fußgänger, aber z.B. nicht mir, das Unentscheidbarkeitsaxiom oder hat einsetzen.
.b hinwiederum ist zu lesen: was unmittelbar nach einer finiten Form von haben und unmittelbar vor einem Partizip Perfekt steht. Da können alle Elemente eingesetzt werden, die schon in .a einsetzbar waren, und zusätzlich mir und das Unentscheidbarkeitsaxiom, jedoch weiterhin nicht hat.
Die einfachste Feststellung bzgl. des Gebrauchs einer sprachlichen Einheit betrifft die Frage, ob sie in einem gegebenen Kontext vorkommt oder nicht vorkommt. Z.B. kommt das deutsche Morph -em nach den Morphen schön, lang, alt vor, nicht jedoch nach den Morphen Frau, Mann, Kind. Nachdem man genug Beispiele von Kontexten gesammelt hat, in denen die zu untersuchende sprachliche Einheit vorkommt, versucht man, diese Kontexte zu kategorisieren. D.h. man verlängert nicht die Liste schön, lang, alt um klug, kurz, neu ... mit dem Ziel, die möglichen Kontexte aufzuzählen; sondern man stellt die Kategorie fest, der alle diese Kontexteinheiten angehören, und gibt statt dessen diese in der Kontextspezifikation der zu untersuchenden Einheit an, ähnlich wie in .b oben. Im vorliegenden Falle wäre das also: “unmittelbar nach einem Adjektivstamm”, oder formaler: [[X]Adj.stamm __]Adj.form. Näheres zur Methodik unten.
Paradigmatische Relationen
Die einfachste Feststellung über die paradigmatische Relation zwischen zwei sprachlichen Einheiten betrifft die Frage, ob sie im selben Kontext bzw. – mit leichter Generalisierung – in derselben Klasse von Kontexten vorkommen oder nicht. Diese einfache Tatsache ist die Basis der Unterscheidung der drei allgemeinsten paradigmatischen Relationen:
Zwei sprachliche Einheiten stehen in Opposition (engl. contrast),1 wenn sie in denselben Kontexten vorkommen, wenn also die Ergebnisse ihrer Substitution mit dem Sprachsystem vereinbar sind, aber etwas Verschiedenes bedeuten bzw. verschiedene Funktion haben. Das trifft z.B. auf die beiden Morpheme der deutschen Adjektivsteigerung zu, die in aufgeführt sind; denn sie kommen beide gleich nach einem Adjektivstamm vor, leisten da aber Verschiedenes.
| . | dt. -er Komparativ : -st Superlativ |
Zwei Ausdrücke, die sich nur in einem einzigen Morph an einer gegebenen Position unterscheiden, bilden ein grammatisches Minimalpaar. ist ein Beispiel. Das Bestehen eines solchen Minimalpaars beweist, daß die beiden betreffenden Morphe im selben Kontext vorkommen können. Wenn nun die beiden Ausdrücke Verschiedenes bedeuten bzw. verschiedene Funktionen erfüllen, stehen die beiden Morphe in Opposition.
| . | dt. schön-er-e : schön-st-e |
Zwei sprachliche Einheiten stehen in komplementärer Verteilung (engl. complementary distribution), wenn sie keinen Kontext gemeinsam haben, so daß sich ihre Distributionen nicht überlappen, sondern ergänzen.2 Die Konjugationsendungen der 1. Ps. Sg., wie in , sind ein Beispiel.
| . | dt. -e ~ ∅ 1. Ps. Sg. (wie in sing-e ~ sang-∅) |
Die komplementäre Verteilung zweier Einheiten deutet darauf hin,
- daß der Kontext der konditionierende Faktor für das Auftreten der einen oder der anderen ist, m.a.W. daß es kombinatorische Varianten sind;
- daß die beiden Einheiten dieselbe Bedeutung oder Funktion haben.
Zwei sprachliche Einheiten stehen in freier Variation, wenn sie dieselbe Verteilung haben, ohne daß die Substitution der einen durch die andere einen semantischen oder funktionalen Unterschied ergibt. ist ein Beispiel.
| . | dt. -chen ~ -lein (wie in Häuschen ~ Häuslein) |
Bei den letzteren beiden Relationen liegt funktionale Äquivalenz (Synonymie) vor.
Neben den soeben definierten drei paradigmatischen Relationen gibt es einen vierten logisch möglichen Fall: zwei sprachliche Einheiten haben verschiedene, nicht jedoch komplementäre Verteilung. Z.B. Erna und erwachte. (Die Verteilung ist nicht komplementär, weil die beiden Verteilungen nicht gemeinsam eine einheitlich bestimmte Menge von Kontexten erschöpfen.) Solche Einheiten haben i.a. unterschiedliche Bedeutung/Funktion. Ihre paradigmatische Relation ist nicht definiert. Paradigmatische Relationen sind nur definiert für eine gegebene syntagmatische Position nebst ihrem logischen Gegenteil, denn die Begriffe der paradigmatischen Relationen unterstehen dem Ziel, die im Sprachsystem relevanten Einheiten und Kategorien zu identifizieren. Noch anders gesagt: Einheiten, die solchen verschiedenen Kategorien angehören (wie hier ‘Substantiv’ und ‘Verb’), sind dazu bestimmt, syntagmatische Relationen einzugehen; die Frage einer paradigmatischen Relation zwischen ihnen ist schon erledigt dadurch, daß sie überhaupt verschiedenen Kategorien zugeordnet wurden.
| 1. | Paradigmatische Relationen allgemein |
| 2. | Paradigmatische Relationen in der Morphologie |
Syntagmatische Relationen
Syntagmatische Relationen bestehen zwischen Einheiten desselben Typs auf derselben Komplexitätsebene oder zwischen benachbarten Komplexitätsebenen. Die grammatischen Komplexitätsebenen, meist einfach grammatische Ebenen genannt, sind die folgenden:
| Einheit | Beispiel |
|---|---|
| Satz | Wer andern eine Grube gräbt, fällt selbst hinein. |
| Klause | wer andern eine Grube gräbt |
| Syntagma | andern eine Grube gräbt |
| Wort(-form) | gräbt |
| Morphem | -t |
Z.B. hat das Morph -t eine syntagmatische Relation zu dem Morph gräb-, die u.a. dadurch charakterisiert ist, daß es ein Suffix zu letzterem ist und eine Leerstelle von ihm markiert. Es bildet mit diesem zusammen die nächsthöhere Einheit der Wortform gräbt.
Das Ebenensystem wird anderswo näher erläutert. Die einzelnen Ebenen werden in den betreffenden Kapiteln über strukturale Morphologie und Syntax definiert.
Substitution und Permutation
Um den Status von Einheiten zu ermitteln, stellt man ihre paradigmatischen und syntagmatischen Relationen fest. Die Methoden, dies zu tun, sind pro Dimension eine Art von Manipulation der zu testenden Einheit:
| Relation | Manipulation | Test |
| paradigmatisch | Substitution | Ersatzprobe |
| syntagmatisch | Permutation | Verschiebeprobe |
Der Zweck der Substitutionsprobe ist es, die in der Sprache bestehenden Klassen (oder Kategorien) zu finden. Der Zweck der Permutationsprobe ist es, die in der Sprache bestehenden Konstruktionen zu finden. Es wird kein Vorwissen über die sprachlichen Einheiten vorausgesetzt, da diese eben erst gefunden werden sollen. Insbesondere kann man die Proben auf Einheiten beliebigen Umfangs, also z.B. auf Wortformen ebenso wie auf Wortketten anwenden, und man kann auch eine Kette durch ein einzelnes Wort ersetzen.
Eine wichtige Form der Substitutionsprobe ist die Weglaßprobe (Substitution durch Null). Ergibt sich bei der Weglassung der betreffenden Einheit kein Ausdruck der Sprache (ist das Ergebnis der Manipulation ungrammatisch), so ist die Einheit in diesem Kontext obligatorisch; andernfalls ist sie optional. Z.B. ist in .a fuhr obligatorisch, aber in die Garage optional.
Oft will man wissen, ob eine Teilkette eine sprachliche Einheit (ein Syntagma i.w.S.) ist. Dazu substituiert man sie durch eine elementare Einheit (einschließlich Null).
| . | a. | Erna fuhr den Wagen in die Garage. |
| b. | Erna fuhr den Wagen hinein. | |
| c. | Erna fuhr den Wagen. |
Die Substitutionen von werden in dem Kontext ‘Erna fuhr den Wagen __’ vorgenommen. Die in vorgenommenen Substitutionen sprechen dafür, daß in die Garage ein Syntagma ist. Würde man auf entsprechende Weise Teilketten wie Erna fuhr oder Wagen in die ersetzen, würde man feststellen, daß es keine Syntagmen sind.
Obwohl diese Methoden intellektuell sehr schlicht wirken, setzen sie doch ein hohes Maß an Kontrolle voraus. Erstens hat man jedenfalls den Kontext konstant zu halten. Angenommen, die Frage ist, ob man in dem Kontext von .a (oder, formaler, in dem Kontext [__ alte Männer]) viele durch alle substituieren kann. Die Antwort “ja; dann ergibt sich .b” verfehlt den Sinn der Ersatzprobe. Es ist im Gegenteil ein wichtiges Ergebnis dieses Tests, daß die Substitution nicht möglich ist, denn daraus folgt, daß viele und alle, wiewohl in vielen Schulgrammatiken zur selben Wortart gerechnet, nicht in dieselbe Distributionsklasse und also auch nicht ohne weiteres in dieselbe Wortart fallen.
| . | a. | viele alte Männer |
| b. | alle alten Männer |
Zweitens hat man die Bedingungen zu kontrollieren, welche man an die Sprachrichtigkeit des Ergebnisses der Manipulation stellt. Folgende drei Fälle sind zu unterscheiden:
- Das Ergebnis der Substitution/Permutation ist grammatisch, und die Bedeutung ändert sich gegenüber der Ausgangsfassung nicht.
- Das Ergebnis des Tests ist grammatisch, aber die Bedeutung ändert sich.
- Das Ergebnis des Tests ist ungrammatisch.
Das Ergebnis 1 verwendet man als Argument für die Analyse, daß Ausgangs- und Zielfassung in freier Variation stehen.
- Im Falle einer Substitutionsprobe kann das bedeuten, daß zwei substituierte Einheiten synonym sind. Bsp.: ehe und bevor in __ wir anfangen. Wurde eine Einheit durch Null substituiert, so spricht das Ergebnis dafür, daß sie optional ist und nichts zur Bedeutung beiträgt (ein Ausnahmefall). Bsp.: nicht in Ich rede nicht mehr mit dir, bevor du dich __ entschuldigt hast.
- Im Falle einer Permutationsprobe kann man – in dem gegebenen Rahmen – für freie Wortstellung argumentieren. Bsp.: daß ich das T-Shirt dem Universitätssenat gestiftet habe vs. daß ich dem Universitätssenat das T-Shirt gestiftet habe.3
Das Ergebnis 2 verwendet man als Argument für die Analyse, daß Ausgangs- und Zielfassung in Opposition stehen.
- Im Falle einer Substitutionsprobe wird man schließen, daß die substituierten Einheiten zu einer Substitutionsklasse gehören. Beispiele: träge und faule in eine __ Studentin. Wurde eine Einheit durch Null substituiert, so spricht das Ergebnis dafür, daß die Einheit (und ggf. ihre Klasse) zwar grammatisch optional ist, jedoch einen kompositionellen Beitrag zur Gesamtbedeutung leistet. Bsp.: träge in eine __ Studentin.
- Im Falle einer Permutationsprobe kann man schließen, daß die Konstruktionsbedeutung mit der syntagmatischen Position der Einheiten zusammenhängt. Beispiel: frz. pauvre soldat ‘armer (i.e. bedauernswerter) Soldat’ vs. soldat pauvre ‘armer (i.e. mittelloser) Soldat’.
Aus dem Ergebnis 3 kann man zunächst nichts Bestimmtes schließen (ich erinnere an den letzten Absatz von §2 oben).
- Im Falle der Substitutionsprobe kann weitere Untersuchung ergeben, daß man die beiden betreffenden Einheiten überhaupt in keinem Kontext füreinander substituieren kann; dann wäre es ein Fall von komplementärer Verteilung. Bsp.: -en vs. -er z.B. in Frau__ und Kind__. Es kann auch sein, daß die Einsetzung einer Einheit in eine Position eine bestimmte Veränderung im Kontext konditioniert, so wie das offenbar in der Fall ist.
- Im Falle der Verschiebeprobe kann sich z.B. ergeben, daß jegliche Verschiebung der fraglichen Einheit ungrammatisch ist; dann schließt man auf eine feste syntagmatische Position. Bsp.: für in wir votierten __ den Dekan.
Die Analysemethoden sind insoweit asemantisch, als sie kein Wissen darüber voraussetzen, was ein Ausdruck bedeutet oder worin ein Bedeutungsunterschied besteht. Das einzige vorausgesetzte semantische Wissen besteht darin, daß man angeben kann, ob ein Ausdruck sinnvoll ist und ob zwei Ausdrücke dasselbe bedeuten oder nicht. Diese Bedingung ist methodisch wichtig, da die semasiologische Perspektive die Bedeutung ja herausbekommen will, also nicht voraussetzen kann.
Wir kommen anhand einer Substitution durch eine elementare Einheit noch einmal auf das Erfordernis der Konstanthaltung des Kontextes zurück. soll dazu dienen, durch Substitutionsprobe zu beweisen, daß die Teilkette weiß mein Freund in .a ein Syntagma ist.
| . | a. | Ich weiß mein Freund war dabei. |
| b. | Ich selbst war dabei. |
Da man (außerhalb dieser Methode) weiß, daß die Segmentierung ‘ich | weiß mein Freund | war dabei’ unangemessen ist, will man einen solchen Beweis nicht zulassen. Sein Fehler liegt darin, daß die syntagmatischen Relationen der im Kontext verbleibenden Einheiten in a und b verschieden sind (in #b ist ich Subjekt zu war, in #a nicht).
Während man die paradigmatischen Relationen testet (also substituiert), muß man also nicht nur den Kontext, sondern auch die syntagmatischen Relationen konstant halten. Während man die syntagmatischen Relationen testet (also permutiert), muß man die paradigmatischen Relationen, also die Kategorien der betroffenen Einheiten, konstant halten. Das Analyseverfahren ist also insoweit zirkulär. Das bedeutet, daß das Verfahren keine Entdeckungsprozedur ist, also kein Verfahren, das nur mechanisch angewandt zu werden braucht und dann die richtige Analyse liefert. Vielmehr ist es eine Rechtfertigungsprozedur, d.h. ein Verfahren, mit dem man ex post beweist, daß die vorgelegte Analyse wissenschaftlichen Kriterien standhält. Näheres hierzu anderswo.
| 1. | Substitutionsklassen |
| 2. | Substitution und Permutation |
| 3. | Methodische Kontrolle |
Distribution
Die Distribution (Verteilung) einer sprachlichen Einheit ist die Gesamtheit der Kontexte, in denen sie vorkommt.
Zwei sprachliche Einheiten gehören derselben Distributionsklasse an genau dann, wenn sie dieselbe Distribution haben. Der Begriff der Distributionsklasse umfaßt intensional den (weniger interessanten) der Substitutionsklasse (d.h. Distributionsklassen sind i.a. kleiner als Substitutionsklassen), weil zwei Einheiten bereits dann einer Substitutionsklasse angehören, wenn sie in einem gegebenen Kontext füreinander substituiert werden können.
Betrachten wir als Beispiel die Menge der Wörter in .
| . | Berlinerin, Erna, Schreckschraube, Studentin, Mata Hari, Schmidt |
Das sind alles Substantive. Die Frage ist, ob die Wörter dieselbe Distribution haben, also in dieselbe Distributionsklasse fallen. Wenn ja, kann die Klasse ‘Substantiv’ als Distributionsklasse aufgefaßt werden, andernfalls nicht.
Um solche Fragen zu beantworten, geht man wie folgt vor:
1. Man bildet Sätze, in denen solche Wörter vorkommen. Die Wörter von kommen z.B. in Sätzen wie und vor:
| . | Die Schreckschraube kommt (nicht). |
| . | Erna kommt (nicht). |
2. Im nächsten Schritt abstrahiert man aus solchen Sätzen die Kontexte, in denen die zu untersuchenden Wörter auftreten. Im folgenden ist der Kontext K1 eine Abstraktion über Sätzen wie , und K2 ist eine Abstraktion über Sätzen wie (‘##’ steht für Satzgrenze, also den absoluten Beginn [und das absolute Ende] des Satzes).
| K1. | ## die ___ [Verbform der 3. Ps. Sg.] |
| K2. | ## ___ [Verbform der 3. Ps. Sg.] |
3. Als nächstes setzt man jedes der zu untersuchenden Wörter in alle Test-Kontexte ein und sortiert sie danach, in welchen Kontexten sich dabei grammatische Konstruktionen ergeben. Spätestens jetzt wird man darauf aufmerksam, daß sich die Stile, Dialekte und Soziolekte in diesem Punkte unterscheiden. Die Varietät der Sprache, für welche man eine solche Frage beantworten will, muß man von vornherein festlegen, also nicht erst ad hoc für ein gegebenes Beispiel. Wir verstehen hier unsere Eingangsfrage so, daß sie sich auf das Schriftdeutsche bezieht. Dann lassen sich die Substantive wie folgt in die beiden Kontexte einsetzen:
| Kontext | einsetzbare Wörter |
|---|---|
| K1 | Berlinerin, Schreckschraube, Studentin |
| K2 | Erna, Mata Hari, Schmidt |
K1 und K2 definieren also je eine Substitutionsklasse.
4. Im vorliegenden Fall stellt man fest, daß jedes der Wörter in genau eine der aufgestellten Substitutionsklassen fällt. Nicht immer ist es so einfach. Theoretisch könnte es eine weitere Klasse von Substantiven geben, die in beiden Kontexten vorkommen können, etwa Heulsuse o.ä. Man definiert daher nunmehr Distributionen als Menge von Kontexten und Distributionsklassen auf der Basis dieser Distributionen:
| Distributionsklasse | zugehörige Kontexte |
| D1 | K1 |
| D2 | K2 |
Wie gesagt, könnte es noch D3: K1 & K2 geben.
5. Damit ist die gestellte Frage wie folgt zu beantworten: Die Wörter in haben verschiedene Distribution. Sie fallen folglich in verschiedene Distributionsklassen. Diese Distributionsanalyse ergibt also keinen Hinweis darauf, wieso alle Wörter in traditionell zu einer Klasse (Substantiv) zusammengefaßt werden.
Nachzutragen ist, daß D1 und D2 traditionelle Namen haben, nämlich Appellativum und Eigenname.
| 1. | Adverbien als Distributionsklassen |
1 Der Ausdruck opposition kommt zwar in englischen Texten in der hier relevanten Bedeutung vor, aber contrast ist viel gebräuchlicher. Das ist zu bedauern, weil der Ausdruck contrast eigentlich als Terminus für den Begriff ‘Kontrast’ benötigt wird.
2 Eine bestürzende Menge von (promovierten) Linguisten kriegt den Unterschied zwischen Opposition und komplementärer Verteilung nicht klar. Insbesondere ist häufig, wenn von komplementärer Verteilung die Rede ist, in Wahrheit Opposition gemeint.
3 Wenn man strengere Maßstäbe an Synonymie anlegt, sind die beiden Fassungen allerdings nicht synonym, insofern sie sich in ihrer Informationsstruktur unterscheiden.