Auditive Phonetik ist perzeptuelle Phonetik. Sie untersucht die physiologischen Vorgänge beim Hören. Aus anderer disziplinärer Perspektive ist auditive Phonetik der Teil der Psychoakustik und der Sinnesphysiologie, der sich auf die Wahrnehmung von Sprachlauten konzentriert.
Umsetzung akustischer Parameter in auditive Qualitäten
Die im vorigen Kapitel behandelten akustischen Größen sind meßbar und also objektivierbar. Sie werden jedoch nicht objektiv wahrgenommen. Einerseits bestimmt sich das Wahrgenommene nach den Fähigkeiten des Wahrnehmungsorgans. Zum anderen tritt in der Apperzeption dazu eine Kategorisierung und Wertung. Die folgende Tabelle stellt dar, was der Mensch an den verschiedenen akustischen Eigenschaften von Schällen hört.
Lautstärke: wird i.w. durch Schalldruck bestimmt. Die Zunahme auf diesem physikalischen Parameter entspricht jedoch nicht linear, sondern ungefähr logarithmisch dem auditiven Eindruck. Z.B. wird ein Schalldruck von x4 Pa als doppelt so laut wie ein Schalldruck von x2 Pa empfunden. Wird gemessen in Dezibel (dB) = Phon.1 Der Nullpunkt der Dezibel-Skala ist auf einen gerade noch hörbaren Schall gesetzt. Wenn Schall x die doppelte Lautstärke hat wie Schall y, hat x 5 dB mehr als y. Ein Lautstärkenunterschied in 1 dB ist gerade hörbar.
Lautstärkenunterschiede werden am besten in dem Frequenzbereich zwischen 200 und 5.000 Hz (das ist gerade der für Sprache relevante Bereich!) wahrgenommen, unterhalb und oberhalb dieser Schwellen jedoch deutlich schlechter. Deshalb wird die Lautstärke nach der Frequenz gewichtet. Eine der Formeln für die Gewichtung ist die A-Gewichtung. Daher auch die Bezeichnung 'dBA'.
Schallpegelskala
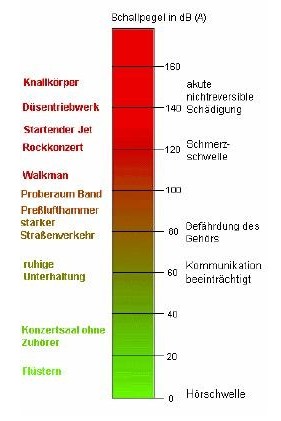
nach dem ehemaligen Skript https://iem.at/lehre/skripten/skriptum.pdf des Instituts für Elektronische Musik und Akustik, Graz vom 05.07.2007
Tonhöhe (engl. pitch): basiert auf der Grundfrequenz, mit leichter Verzerrung durch Lautstärke. Die Zunahme auf diesem physikalischen Parameter hat eine komplexe Entsprechung im auditiven Eindruck. Bis etwa 1.000 Hz ist die Entsprechung linear, von da an ungefähr logarithmisch. Im Bereich von 100 Hz hört man einen Frequenzunterschied von 4 Hz, im Bereich von 4.000 Hz einen Unterschied erst ab 40 Hz.
Die Tonhöhe ist (neben Lautstärke und Dauer) der Hauptfaktor in der auditiven Prominenz lautlicher Einheiten.
Die Tonhöhe von Klängen orientiert sich ausschließlich am Grundton. Wird dieser technisch aus dem harmonischen Spektrum entfernt, hört man ihn dennoch ("Phantomgrundton"); d.h. er wird aus den Obertönen erschlossen.
Das Frequenzintervall einer Oktave ist ein Verhältnis von 2 / 1. Z.B. hat A 440 Hz und a' 880 Hz. Folglich ist bei gleichtemperierter Stimmung ein Ton vom nächsten Halbton um den Faktor 21/12 (~ 1,06) in der Frequenz entfernt. Ist die Frequenz von A = 440 Hz, dann ist die von B = 440 * 21/12 = 465 Hz.
Hörbereich
Die physikalischen Eigenschaften von Schällen werden wie folgt vom Ohr wahrgenommen:
- Schalldruck: Der Schalldruck des lautesten Schalles, den man verkraften kann, ist etwa 10 Mio mal höher als der Schalldruck des leisesten hörbaren Schalls.
Töne, die keine klare tonale Prominenz haben, haben unbestimmte Tonhöhe. Folgende Musikinstrumente produzieren solche Töne: Pauke, Becken, Triangel, Kastagnetten, Tambourin und die gesprochene Sprache.
Auditive Intensität: auditive Eigenschaft eines Schalls: Stärke der Wirkung auf das Gehör. Wächst mit dem Schalldruck, der Frequenz (bis zu ca. 10.000 Hz) und Dauer. Da der Schalldruck mit der Entfernung der Schallquelle vom Wahrnehmenden abnimmt, gilt das auch für die Intensität.
Klangfarbe (Timbre) eines komplexen Schalls, bes. eines musikalischen Tons oder eines Sprachlauts, ist die auditive Entsprechung zur Energieverteilung in seinem Schallspektrum. In der Klangfarbe unterscheiden sich z.B. Musikinstrumente, Vokale.
Formant: Bündel von Obertönen ungefähr gleichhoher Intensität, das einen Abschnitt der Frequenzskala abdeckt und daher einen Sprachlaut akustisch mitkonstituiert. Die Klangfarbe eines Sprachlauts setzt sich zusammen aus seinen Formanten.
Die schwarzen Bänder in einem Spektrogramm (z.B. dem in Lektion 2 vorgeführten) sind die Formanten der dort wiedergegebenen Vokale.
Da das Schallspektrum eines komplexen Schalls durch die Konfiguration seiner Resonanzräume mitbestimmt wird, gilt dies auch für die Formanten von Sprachlauten. Die Formanten werden, beginnend bei demjenigen mit der tiefsten Frequenz, von unten nach oben durchgezählt. F0 ist die Grundfrequenz. Für Sprachlaute sind i.a. nicht mehr als fünf relevant. Sie sind besonders wichtig bei der akustischen Definition der Vokale. S. Kap. 5.3.
Simultane und sequentielle Struktur von Sprachlauten
Die vertikale oder simultane Struktur eines Schalls bzw. eines Abschnitts eines Schalls ist die Gesamtheit seiner gleichzeitigen Eigenschaften, also sein Spektrum.
Die horizontale oder sequentielle Struktur eines Schalls ist sein Verlauf in der Zeit.
In beiden Dimensionen ist das Differenzierungsvermögen des menschlichen Gehörs merklich feiner, als es für die Verarbeitung von Sprachlauten nötig ist; aber es ist in dem Bereich am feinsten, in dem Sprachlaute übertragen werden (s.u.).
Simultane Dimension
Die Grundlage des Differenzierungsvermögens in der simultanen Dimension ist der Hörbereich: eine Schwingung bzw. Welle im Übertragungsmedium ist nur dann ein Schall, wenn sie innerhalb des menschlichen Hörbereichs liegt.
- Dazu muß die Frequenz zwischen 16 und 20.000 Hz liegen; bei älteren Menschen noch niedriger. Kleinere Frequenzen liegen im
Infra-, größere im Ultraschallbereich.2 - Ebenso muß die Lautstärke innerhalb eines bestimmten Bereichs liegen: liegt der Schalldruck bei einem Ton von 1 kHz unter 20μPa = 0dBA, ist die Schwingung nicht hörbar, liegt er über 100 Pa (Schwankung des Luftdrucks um über 1/1000 seines Werts) = 130 dBA, resultiert Schmerz statt Schall (vgl. Größenordnungen des Schalldrucks)
Menschlicher Hörbereich
 (www.substream.org (<- tecchannel.de)
(www.substream.org (<- tecchannel.de)
Die in Sprachlauten enthaltene phonetische Information liegt im Frequenzbereich von etwa 300 bis 4.000 Hz. Der Hörbereich schließt trivialerweise die Reichweite der menschlichen Stimme ein. Das Differenzierungsvermögen ist gerade in den Frequenz- und Intensitätsabschnitten am besten, wo die Formanten menschlicher Sprache liegen.
Die Abbildung zeigt übrigens gut, daß man bei ganz geringem Schalldruck nur noch Frequenzen um etwa 4 KHz hört. Das ist genau der Bereich, in dem die Formanten von Sibilanten liegen. Beim Flüstern werden niedrigere Frequenzen unterdrückt. Daher klingt Flüstern wie ein Gezischel.
Das Differenzierungsvermögen schließt insbesondere die Unterscheidung von Klangfarben ein. Eine Klangfarbe setzt sich aus einer großen Zahl von Einzelwerten zusammen, welche die relative Höhe und die relative Lautstärke der einzelnen Komponenten eines komplexen Schalls betreffen. Mindestens fünf solcher Komponenten – bei Sprachlauten eben die Formanten – können auseinandergehalten werden. Relativ sind die Werte deswegen, weil die absoluten Werte für das Sprachsystem von keinem Belang sind. Ein /a/ ist ein /a/, gleichgültig ob es von einem kleinen Kind oder einem alten Mann gesprochen, ob es von einer Sopranistin oder einem Baß gesungen wird. Nicht nur die Grundfrequenz, sondern sämtliche Obertöne nehmen bei solcher individueller Variation unterschiedliche absolute Werte an. Für die Identifikation eines /a/ ist aber nur wichtig, wie relativ prominent die einzelnen Komponenten sind und wie weit der Frequenzabstand der einzelnen Komponenten im Verhältnis zu anderen Mitgliedern des Paradigmas und des Syntagmas ist. In diesem Punkte leistet das menschliche Gehör Außerordentliches, und zwar im Reich der Sprachlaute ebenso wie in dem der musikalischen Klänge. Mehrere höhere Tiere, z.B. Hunde, können nachweislich keine Sprachlaute unterscheiden.
Sequentielle Dimension
In der sequentiellen Dimension werden Formantübergänge bis hinunter zur Dauer von 30ms differenziert (Clark & Yallop 1995:308). Mehrere für die sprachliche Lautstruktur relevante Merkmale werden nicht in Oppositionen, sondern im Kontrast wirksam. Das gilt vor allem für den Merkmalkomplex 'sonor/prominent/silbisch'. In der Phonologie gibt es hierfür eine eigene Subdisziplin, die Phonotaktik. In der Phonetik ist die Untersuchung der sequentiellen Struktur des Sprachlauts unterentwickelt.
Klassifikation von Sprachlauten nach auditiven Eindrücken
Die vertikale Struktur von Sprachlauten wird durch Merkmale wie 'kompakt vs. diffus' beschrieben, die horizontale durch Merkmale wie 'dauernd vs. abrupt'. Die Tabelle zeigt einige in der Wissenschaft wohletablierte auditiv konzipierte phonetische Merkmale:
| phon. Merkmal | Beispiel | akustischer Parameter |
|---|---|---|
| dauernd vs. abrupt | [s] vs. [t] | Dauer |
| hoch vs. tief | [á] vs. [à] | Frequenz |
| dunkel vs. hell | [u] vs. [i] | Klangfarbe: Frequenz F2 |
| scharf vs. sanft | [s] vs. [θ] | Klangfarbe: Frequenz F4 |
| kompakt vs. diffus | [a] vs. [i] | Klangfarbe: Distanz F1 - F2 |
Daneben gibt es noch weitere, die zu definieren bleiben.
Verstehen
Die auditive Phonetik behandelt das Verstehen - genauer den phonetischen Teil davon, der auf Englisch ‘speech perception’ heißt - als einen ‘Bottom-up-Prozeß’, wo dem Hörer nur die im Schall kodierte Information vorliegt und er daraus das vom Sprecher Gemeinte rekonstruiert. Tatsächlich ist aber Redeverstehen großenteils ein ‘Top-down-Prozeß’, in dem der Hörer den Sprecher in seiner Planung begleitet. Dieser Aspekt bleibt in der auditiven Phonetik typischerweise unberücksichtigt.
Ziel des Hörers ist es, den Gedanken zu rekonstruieren, den der Sprecher übermitteln wollte. Er geht aus von dem Input, der in Form von kontinuierlichen akustischen Reizen auf sein Ohr trifft. Diesen analysiert er im Hinblick auf die diversen für Sprachlaute wesentlichen auditiven Eigenschaften und wandelt die kontinuierlichen Signale in eine diskrete Repräsentation. Er muß - ähnlich einem strukturalen Linguisten - die Inputkette zunächst segmentieren, also in eine Kette von phonetischen Einheiten wandeln. Diese Einheiten wiederum muß der Hörer nach Grundsätzen der paradigmatischen und syntagmatischen Variation klassifizieren. Zur Analyse wendet er die Kategorien seines Sprachsystem - seines Lautsystems - an und ignoriert alle dafür irrelevante Information (vgl. das Beispiel des Stimmeinsatzzeitpunkts). So erstellt er die lexikalische Repräsentation der Significantia der benutzten Sprachzeichen. Diese kann er schließlich dekodieren, d.h. mit ihren Significata assoziieren. Von da ist es noch ein weiter Weg bis zum Verständnis dessen, was der Sprecher wollte; aber dazu hat die Phonetik nichts mehr beizutragen.
Testfragen und Übungsaufgaben
- (1 P.) Worin liegt der Unterschied im Gegenstandsbereich zwischen akustischer und auditiver Phonetik?
- (1 P.) Welche akustische Größe liegt der Lautstärke eines Schalls zugrunde?
- (1 P.) Welchen auditiven Eindruck bestimmt die Frequenz eines Schalls?
- (1 P.) Was ist die akustische Grundlage der Klangfarbe eines Schalls?
- (2 P.) In welchem Frequenzbereich liegt die zur Unterscheidung von Sprachlauten nötige akustische Information?
- (2 P.) In welchem Dezibelbereich pflegt sich Sprache abzuspielen?
- (1 P.) Wie heißen die Komponenten der Klangfarbe eines Sprachlauts?
- (2 P.) Woraus besteht, akustisch betrachtet, ein Formant?
- (3 P.) Warum können die absoluten Werte der akustischen Eigenschaften nicht das Wesen der Sprachlaute bestimmen?
1 Nach Angelo Campanella 1998 (Webseite) wird die Lautstärke in Son gemessen. 1 Son = 40 Phon. Eine Zunahme um 10 Phon ergibt die doppelte Lautstärke in Son.
2 Zum Vergleich: Die Frequenz, mit der ein Specht klopft, ist maximal 20 Hz. Bei maximaler Performanz - aber nur dann - hält man also die einzelnen Schläge nicht mehr auseinander.