Die Lehre von den syntagmatischen Relationen in der Phonologie ist die Phonotaktik. Im Unterschied zu der Lehre von den phonologischen Prozessen betrachtet die Phonotaktik syntagmatische Relationen zwischen distinktiven (oder zugrundeliegenden) Einheiten auf lexikalischer (morphophonologischer) Ebene. Im Zentrum stehen Silbenstruktur und Morphemstruktur.
Die wesentliche syntagmatische Relation in der Phonologie ist die Prominenz. Auf segmentaler Ebene manifestiert diese sich als Sonorität, auf suprasegmentaler als Akzent.
Silbe
Silbenstruktur
Die Silbe ist die kleinste freie phonologische Einheit. Sie hat genau einen Gipfel und links und rechts optional einen Rand. Die beiden Ränder unterscheiden sich allerdings darin, daß in der optimalen Silbe der linke vorhanden, der rechte nicht vorhanden ist. Der akustische Verlauf kann schematisch wie folgt dargestellt werden:
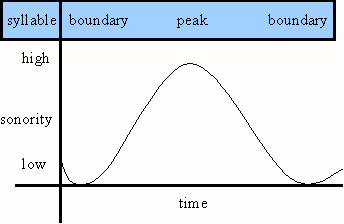
Der Gipfel (Nukleus oder Kern) ist das Segment mit der höchsten Prominenz. Diese ist im einfachsten Fall durch seine Sonorität bestimmt. Die Anzahl der Silbengipfel in einer größeren phonologischen Einheit ist normalerweise eindeutig. Die einzige mögliche Komplikation bieten hier Präinitial und Postcoda (s.u.). Die Grenzen zwischen den Silben dagegen sind nicht notwendigerweise klar. Sie liegen am Sonoritätsminimum, normalerweise unmittelbar davor.
Der Silbengipfel ist normalerweise ein Vokal. Wenn keiner vorhanden ist, kann es auch eine Liquida sein, wie in dt. Teufel ['tɔɩ•fl̩], kroatisch Krk, oder ein Nasal, wie in dt. laufen ['laʊ•fn̩], swahili mtu 'Mann'. In besonderen Fällen wie dt. psst kommt auch ein Frikativ infrage.
Silbische und nichtsilbische Varianten von Vokalen (Halbvokalen) und Liquiden sind normalerweise in komplementärer Verteilung. Ob die Möglichkeit der Opposition besteht, wie in B1 und B2, ist umstritten. Die silbischen Varianten sind länger.
| B1. | Schreibung | Laut | Bedeutung |
| Engl | coddling | /'kɔd•l̩•liŋ/ | am hätscheln |
| codling | /'kɔd•liŋ/ | Kabeljaulein |
| B2. | Schreibung | Laut | Bedeutung |
| Lat | VOLVIT | /'woluit/ | wollte |
| VOLVIT | /'wolwit/ | dreht |
Der linke Silbenrand heißt Ansatz (auch “Anfangsrand”), der rechte Coda (auch “Endrand”). Gipfel und Coda bilden zusammen den Reim der Silbe. Eine Silbe ohne Coda (und Postcoda) heißt offen, eine Silbe mit Coda (oder Postcoda) geschlossen.
Damit hat eine Silbe die folgende allgemeine Struktur, dargestellt als Konstituentenstruktur und mit dem deutschen Beispiel Strunks in der letzten Zeile:
| Konstituenz | Silbe | ||||||
| Ansatz | Reim | ||||||
| Präinitial | Ansatznukleus | Reimnukleus | Postcoda | ||||
| Initial | Postinitial | Gipfel | Coda | ||||
| Beispiel | ʃ | t | ʁ | u | ŋ | k | s |
Sprachen unterscheiden sich darin, welche der allgemeinen Positionen sie überhaupt besetzen können und wenn ja, mit welchen (Klassen von) Lauten.
Die optimale Silbe hat die folgende Struktur:
| Ansatz | Reim |
| Initial | Gipfel |
| K | V |
Mehrere Sprachen wie Hawaiianisch und Rotokas (beide austronesisch) und Mudburra (Eastern Ngumpin, Pama-Nyunga, Australien) lassen nur Silben dieser Struktur zu (wie in dem hawaiianischen Wort Honolulu).
Viele Sprachen lassen nur eine einzige Komplikation zu, nämlich die in folgendem Schema gezeigte geschlossene gegenüber der offenen Silbe des vorigen Schemas:
Viele Sprachen lassen nur eine einzige Komplikation zu, nämlich die in folgendem Schema gezeigte geschlossene gegenüber der offenen Silbe des vorigen Schemas:
| Ansatz | ||
| Initial | Gipfel | Coda |
| Ki | V | Kj |
Dazu gehören Walmatjari (Westaustralien) und Yukatekisch. (Sprachen wie Mandarin haben sogar noch Beschränkungen über Kj.) In einer solchen Sprache können Konsonantengruppen nur dadurch entstehen, daß auf eine Silbe mit auslautendem Konsonant eine solche mit anlautendem Konsonant folgt. Folglich gibt es keine homosyllabischen Konsonantengruppen, geschweige am Wortanfang.
Die nächste Komplikation gegenüber der optimalen Silbenstruktur besteht in der unten zu besprechenden initialen Konsonantengruppe.
Syllabizität
Die Phonologie einer Sprache kategorisiert die Sprachlaute nach (phonologischen) Sonoritätsklassen. Das System setzt eine Sonoritätsstufe fest, oberhalb welcher ein Laut, wenn er neben Laute niedrigerer Stufe zu stehen kommt, silbisch ist. Die Syllabizität eines Lauts ist seine Eigenschaft, silbisch zu sein, d.h. einen Silbengipfel zu bilden (oder nicht). Dies ist also keine kontextfreie intrinsische Eigenschaft, sondern eine Eigenschaft, die einem Segment (hinreichender Sonorität) im syntagmatischen Kontrast zufällt.
Syllabierung
Es ist umstritten, ob die Silbenstruktur ein Derivat der segmentalen Struktur oder dieser vorgeordnet ist. Nimmt man an, daß sie ein Derivat ist, so muß man sie aus der segmentalen Struktur nebst Pausen und morphologischen Grenzen ableiten können. Zur segmentalen Struktur gehört selbstverständlich auch Information über die Sonoritätsklasse der Segmente. Angenommen, es liegt eine Sequenz der Struktur 'KVKV' vor. In der Teilkonfiguration 'VK' folgt einem Segment mit hoher Sonorität ein solches mit niedriger Sonorität. An einer solchen Stelle wird nach einem allgemeinen Prinzip eine Silbengrenze eingesetzt: 'KV∙KV'. In Konsonantengruppen kann es allerdings Schwierigkeiten geben, die Silbengrenze zu lokalisieren.
Nimmt man dagegen an, daß die Silbenstruktur mit ihren Grenzen ein vorgegebenes Raster ist, so braucht man Beschränkungen für die Bestückung der Positionen der Silbenstruktur mit Segmenten verschiedener Klassen.
Wenn in einer Sequenz ABC B höhere Sonorität als A und C hat, dann bildet B normalerweise einen Silbengipfel. Dies ist jedoch dann nicht der Fall, wenn sich links und rechts der Sequenz Silbengipfel befinden (mit noch höherer Sonorität als B) und wenn die Sequenz normalerweise kein Monosyllabon sein könnte (wenn also B nicht zu den kanonischen Silbengipfeln der Sprache zählt). Beispiele: japste, extra (beide zwei-, nicht dreisilbig).
Hier bleibt allerdings die Frage, ob das in der Mitte dieser Wörter auftretende /s/ Präinitial oder Postcoda ist. Die strukturelle Ambiguität von Präinitial und Postcoda läßt sich wie folgt auflösen: Da Silben der Struktur KV universal bevorzugt sind, während Silben der Struktur VK zwar nicht ausgeschlossen, aber universal dispräferiert sind, fällt in einer Sequenz VKV die Silbengrenze vor den Konsonanten. In Sequenzen von Konsonanten abnehmender Sonorität fällt die Grenze vor den Konsonanten, von dem an die Sonorität bis zum Silbengipfel ununterbrochen steigt. Daher [apf∙tra], [arm∙fla]. Diese Regelung begünstigt Postcoda vor Präinitial. Anders gesagt, das Sprachsystem ist toleranter gegenüber nicht ganz kanonischen Codas als gegenüber zu komplizierten Ansätzen.
Resyllabierung
Angenommen, Silbengrenzen gehören zur lexikalischen Repräsentation eines Significans. Dann würden z.B. trivialerweise Monosyllaba wie dt. her, vor, ein und aus von Silbengrenzen flankiert sein. Werden nun Significantia im Syntagma kombiniert, so können sich Konstellationen wie VK•V oder VKK•V ergeben, wo sowohl die erste als auch die zweite Silbe suboptimal sind. In solchen Fällen wird, wie bereits in Kap. 12 gesehen, normalerweise die Silbengrenze so gesetzt, daß sich optimale Silben ergeben. Aus VK•V wird dadurch V•KV, und aus VKK•V wird VK•KV. Z.B. werden die Wörter herein und voraus normalerweise so syllabiert: he•rein, vo•raus.
Die phonetische Repräsentation ist in solchen Fällen gegenüber der lexikalischen Repräsentation resyllabiert. Der Begriff setzt, wie gesagt, eine Konzeption voraus, in der Significantia bereits vorgängig syllabiert sind. Sind sie das nicht, so findet auf phonetischer Ebene eine einzige Syllabierung statt.
Initiale Konsonantengruppen
Das Vorkommen initialer Konsonantengruppen in den Sprachsystemen wird durch implikative Gesetze wie die in folgender Tabelle aufgeführten bestimmt. A → B bedeutet "Wenn in einer Sprache A vorkommt, kommt auch B vor." Wegen der durch die Großbuchstaben bezeichneten Klassen von Konsonanten s. das Abkürzungsverzeichnis.
| Nr. | markiert | unmarkiert | |
|---|---|---|---|
| 1 | #LK | → | #KL |
| 2 | KL# | → | LK# |
| 3 | #LN | → | #NL |
| 4 | #NK | → | #NG |
| G | → | K | |
| 5 | #GG | → | #KK |
| 6 | #GN | → | #KN |
| 7 | #GW | → | #KW |
| N | → | K | |
| 8 | #NL | → | #KL |
| 9 | #KN | → | #KL |
Die Generalisierungen Nr. 1 - 3 folgen dem allgemeinen Prinzip, daß im einfachsten Falle die Sonorität vom Silbenrand bis zum Gipfel kontinuierlich zunimmt und von da bis zum rechten Silbenrand wieder abnimmt.
Die Generalisierungen Nr. 5 - 7 zeigen, daß am Silbenrand stimmlose vor stimmhaften Plosiven präferiert werden. Dies kann als Optimierung des Kontrasts verstanden werden. Ein ähnliches Prinzip kann man für Nr. 8 anführen.
Über die angeführten Generalisierungen hinaus läßt sich folgendes empirisch feststellen:
- Die Proportion der tatsächlich genutzten zu den logisch möglichen Gruppen nimmt mit der Länge der Gruppe ab.
- Sequenzen sind praktisch immer zusammengesetzt aus Sequenzen, die ebenfalls vorkommen.
- /s/ unterliegt nicht solchen Implikationen wie in der Tabelle, was seinen Sonderstatus als Präinitial und Postcoda bestätigt.
Angenommen, das Raster der Silbenstruktur und die Segmentslots sind vorgegeben und werden (z.B. von einem phonologischen Regelapparat) von links nach rechts gelesen. Dann kann man Markiertheit eines Segments kontextabhängig feststellen, nämlich je nachdem, was unmittelbar vorangeht. Die folgenden Tabellen zeigen dies für das zweite und das dritte Segment eines Worts:
Kontextabhängige Markiertheit von Segmenten
Segmentposition
Merkmal ╲ | 1 | 2 |
|---|---|---|
| konsonantisch | u | u |
| vokalisch | u | u |
| nasal | u | u |
| K | V |
Segmentposition
Merkmal ╲ | 1 | 2 | 3 |
|---|---|---|---|
| konsonantisch | u | m | u |
| vokalisch | u | u | u |
| nasal | u | u | u |
| K | L | V |
An der ersten Position wird ein Obstruent erwartet; wenn ein solcher dort auftritt, haben die Merkmale [vokalisch] und [konsonantisch] den Wert 'u'. Von der zweiten Position an wird der Silbengipfel erwartet, d.h. ein Vokal – der ja die entgegengesetzten ±-Werte hat! – hat von dieser Position an ebenfalls den Wert 'u' für [vokalisch] und [konsonantisch]. Wenn dort diese Merkmale einen anderen Wert haben als [+ vokalisch] und [-kons], dann sind sie 'm'.
Solche Repräsentationen sind unterspezifiziert. Man folgt damit einem allgemeinen Erfordernis der Theorie der Sprachbeschreibung, daß alle Eigenschaften sprachlicher Einheiten, die aus allgemeinen Prinzipien ableitbar sind, in ihrer lexikalischen Repräsentation nicht spezifiziert sein sollten, weil solche Eigenschaften solche Einheiten nicht komplizieren.
Übungsaufgaben
| (6 P.) Englische Junktur |
Literaturhinweise
Cairns, Charles E. 1969, "Markedness, neutralization, and universal redundancy rules." Language 45:863-885.
Greenberg, Joseph H. 1978, "Some generalizations concerning initial and final consonant clusters." Greenberg, Joseph H. (ed.) 1978, Universals of human language. 4 vols. Stanford, Cal.: Stanford University; 1:243-279.
Diphthonge
Ein Diphthong ist eine unmittelbare Folge zweier Vokale im Gipfel einer Silbe. Zwischen diesen besteht ein Prominenzgefälle. D.h., in einem Diphthongen dominiert einer der Bestandteile dadurch, daß er im Syntagma höhere Prominenz als der andere hat (andernfalls würden sie zwei Silben bilden). Deren auditive Grundlage ist höhere Intensität. Der andere Bestandteil, der nicht der absolute Silbengipfel ist, ist dadurch phonologisch unsilbisch.1
Das Prominenzgefälle kommt im einfachsten Falle dadurch zustande, daß einer der beiden Bestandteile höhere Sonorität hat. In diesem Falle determinieren die intrinsischen Eigenschaften der Bestandteile, welcher von beiden der Gipfel des Diphthongen ist. Die beiden Vokale haben also verschiedenen Öffnungsgrad, im häufigsten Falle ist einer [i] oder [u]. Dieser ist dann, da er keine eigene Silbe bildet, phonologisch als Halbvokal analysierbar.
Ein Diphthong mit fallender Prominenz (z.B. [aj]) ist ein fallender Diphthong, ein Diphthong mit steigender Prominenz (z.B. [ja]) ist ein steigender Diphthong. Als Beispiel sehe man das ziemlich symmetrische Diphthongensystem des Spanischen:
| fallend | steigend | ||
| Diphthong | Beispiel | Diphthong | Beispiel |
| aj | Jaime | ja | social |
| aw | causa | wa | anual |
| ej | peine | je | bien |
| ew | deuda | we | bueno |
| oj | boina | jo | ración |
| - | - | wo | arduo |
| - | - | ju | viuda |
| - | - | wi | cuita |
[iw] und [uj] nur als Varianten von [ju] und [wi].
Das Prominenzgefälle in einem Diphthongen kann auch durch andere phonetische Eigenschaften, die die Intensität erhöhen, bewirkt werden, insbesondere durch längere Dauer, größere Gespanntheit, höheren Ton oder Akzentuierung des einen Vokals. In der spanischen Tabelle haben die homosyllabischen Vokale der letzten beiden Einträge dieselbe Sonorität; hier kommt nur durch Akzent auf dem zweiten Vokal ein steigender Diphthong zustande. Es gibt sogar Diphthonge, deren Prominenzgefälle dem Sonoritätsgefälle entgegenläuft. Z.B. hat Lettisch die fallenden Diphthonge /íe/ und /úo/; und Bairisch hat Buab und liab (so schon Saussure 1916).
Stoßen zwei Vokale mit gleichem Öffnungsgrad aufeinander, so ist die Sequenz normalerweise (außer in Fällen wie dem soeben genannten spanischen) heterosyllabisch, d.h. die Silbengrenze zwischen ihnen bleibt zunächst erhalten (Hiatus). So etwa in dt. genuin, Meteor (dreisilbig). Die Zusammenziehung zu einer Silbe heißt Krasis oder Kontraktion. Bei Vokalen mit gleichem Öffnungsgrad verläuft Kontraktion meist unregelmäßig, d.h. unter Schaffung eines Sonoritätsgefälles. Stoßen zwei Vokale aufeinander, die sich im Öffnungsgrad deutlich unterscheiden, so findet meist Synärese statt. Dies ist jedoch nicht obligatorisch; vgl. dt. Lineal, Manual, Museum dreisilbig.
Ein steigender Diphthong läßt sich hinsichtlich der Silbenstruktur im Prinzip auch wie folgt analysieren:
| Ansatz | Reim |
| Initial | Gipfel |
| Halbvokal | Vokal |
| K | V |
Durch diese Analyse rechnet der Halbvokal nicht mehr zum Silbengipfel, und per definitionem verschwindet der Diphthong. Z.B. würde ein Wort wie dt. partiell nicht den steigenden Diphthongen /je/, sondern eine initiale Konsonantengruppe /tsj/ enthalten. Diese Analyse ist im Prinzip nur dann vermeidbar, wenn vor steigenden Diphthongen dieselben Konsonantengruppen wie vor einfachen Vokalen (bzw. fallenden Diphthongen) auftreten. Im Spanischen z.B. gibt es keine Kookkurrenzrestriktionen zwischen initialen Konsonantengruppen und folgenden Diphthongen. Dies ist eher typisch über eine Hauptgrenze hinweg als innerhalb einer Gruppe (des Ansatzes). Hier also kann man den Halbvokal als ersten Bestandteil eines steigenden Diphthongen rechnen.
Ein Silbengipfel besteht im einfachsten Falle aus genau einem Vokal. Die leichteste Abweichung davon, die in vielen Sprachen vorkommt, besteht in einem Gipfel aus zwei Vokalen, eben einem Diphthong. Die äußerste und viel seltenere Abweichung vom Default ist der Triphthong. Ein Triphthong ist eine unmittelbar Folge von drei Vokalen/Halbvokalen im Gipfel einer Silbe, wie in engl. hire, flour.3
Theorie und Methodologie der Phonotaktik
Mögliche Wörter
So wie ein kompetenter Sprecher beurteilen kann, ob ein ihm vorgelegter Satz in seiner Sprache grammatisch ist, kann er auch angeben, ob eine phonologische Gestalt in seiner Sprache möglich ist. Hört z.B. ein Deutscher den Städtenamen Szeged ['sɛgɛd], so weiß er sofort, daß es keine deutsche Stadt sein kann, denn dann könnte ihr Name nicht mit /s/ beginnen und auch nicht auf /d/ enden. Die Wörter einer Sprache sind einerseits dadurch charakterisiert, daß sie bestimmte Phoneme enthalten und andere grundsätzlich nicht enthalten. Sie sind aber auch durch die Distribution der Phoneme charakterisiert. /s/ und /d/ sind zwar im Deutschen vorhanden; aber sie können nicht an denselben Stellen stehen wie im Ungarischen.
Die Phonotaktik formuliert die Bedingungen, denen lexikalische Repräsentationen von Significantia einer Sprache gehorchen, mithin Beschränkungen über mögliche Wörter. Man kann folgende ternäre Unterscheidung machen:
| mögliches Wort | unmögliches Wort | |
|---|---|---|
| bestehendes Wort | nicht bestehendes Wort | |
| /tram/ | /kram/ | /tlam/ |
| /taft/ | /tast/ | /tavt/ |
- Die erste Spalte der Tabelle enthält deutsche Wörter.
- Die Einträge der zweiten Spalte sind keine deutschen Wörter. Sie verletzen aber keine phonotaktische Beschränkung der Sprache. Solche Wörter nennt man zufällige Lücken; gleichzeitig sind es mögliche Wörter. Die Frage “warum ist dies kein deutsches Wort?” hat keine Antwort.
- Die Einträge der letzten Spalte sind ebenfalls keine deutschen Wörter. Sie verletzen phonotaktische Beschränkungen der Sprache. Solche Wörter nennt man unmögliche Wörter oder systematische Lücken. Die Frage “warum ist dies kein deutsches Wort” wird durch Angabe der verletzten Beschränkung beantwortet.
Phonotaktik vs. phonologische Prozesse
Die Gesetze der Phonotaktik haben den Status von Prinzipien der Zusammensetzung zugrundeliegender ("lexikalischer") phonologischer Formen. Sie sind zu unterscheiden von den phonologischen Regeln; diese werden erst angewandt, wenn lexikalische Formen zu einer syntaktischen Konstruktion kombiniert worden sind.
Phonotaktische Prinzipien kann man auf zwei Weisen konzipieren:
- als Formationsregeln, also Regeln, die zulässige Significantia bilden
- als Beschränkungen, die unzulässige Significantia ausfiltern.
Phonologische Regeln dagegen sind jedenfalls Transformationsregeln, d.h. Regeln, die einen Input in einen Output überführen.
Häufig läßt eine Sprache in der phonetischen Struktur genau das zu, was die Phonotaktik verbietet. Z.B.:
- Nasalvokale im Englischen
- silbische Konsonanten im Deutschen
- markierte Konsonantengruppen im Anlaut ([pti] “klein”) und Obstruenten im Auslaut ([ptit] “kleine”) im Französischen.
In solchen Fällen komplizieren also die phonologischen Regeln die phonetischen Repräsentationen.
Häufig ist eine relativ schlichte Phonotaktik gepaart mit einem umfangreichen Apparat phonologischer Regeln, die die zugrundeliegende Systematizität wieder verzerren, während eine komplexe Phonotaktik mit wenigen phonologischen Regeln gepaart ist, die die zugrundeliegende Struktur weitgehend intakt lassen. In beiden Fällen kommt eine phonetische Struktur mittlerer Komplexität heraus.
Für die Analyse ergibt sich das Problem, wieviel von der phonologischen Komplexität einer Sprache man in die Phonotaktik packen soll. Strukturen wie im schon erwähnten frz. petit sind ein einfaches Beispiel. Zwei Beschreibungen sind denkbar: Man kann {ptit} als zugrundeliegende Repräsentation wählen. Dann benötigt man eine phonologische Regel der Schwa-Anaptyxe, die angewendet wird, wenn die Konsonantengruppe silbeninitial ist. Alternativ kann man {pətit} als zugrundeliegende Repräsentation wählen. Dann benötigt man eine Regel der Schwa-Synkope, die den Vokal der ersten Silbe tilgt, wenn eine offene Silbe vorangeht. Die erste Lösung scheint die einfachere zu sein, weil sie weniger Segmente in der zugrundeliegenden Repräsentation spezifizieren muß. Ob sie aber insgesamt gesehen einfacher ist, kann man erst dann entscheiden, wenn man weiß, ob man unabhängig von diesem spezifischen Problem für das Französische eine Regel der Schwa-Anaptyxe oder eine Regel der Schwa-Synkope braucht.
Konditionierung und demarkative Funktion phonologischer Einheiten
In einer englischen Sequenz aus Plosiv plus Liquida kann es Unklarheit über die Silbengrenze geben, wie in dem Minimalpaar nitrate vs. nightrate. In einer Sequenz zweier Plosive kann es eine solche Unklarheit nicht geben, denn es gilt die phonotaktische Beschränkung, daß eine Silbe nicht mit zwei Okklusiven anfangen kann. Hört man folglich eine Sequenz von zwei Plosiven, wie in nightcap, kann man die Silbengrenze lokalisieren. Damit hat man in diesem Falle gleichzeitig die Stammgrenze erkannt - die selbst keinesfalls hörbar ist - und somit das Kompositum in seine Bestandteile zerlegt.
Die deutsche Auslautverhärtung sorgt dafür, daß in der Silbencoda keine stimmhaften Obstruenten auftreten. Hört man daher in einem Wort wie erblich ein [b], so weiß man, daß die Silbengrenze nicht dahinter liegen kann. Folglich muß sie davor liegen; und damit hat man auch in diesem Falle gleichzeitig die Stammgrenze und somit die Voraussetzung für eine morphologische Analyse des Worts.2
Im Deutschen wirkt am Anfang eines vokalisch anlautenden Stammes die Prothese eines Glottisverschlusses. Da er sonst in der Sprache überhaupt nicht vorkommt, signalisiert er den Stammanfang.
Im Kap. 10.2.2.2.2.2 sahen wir den phonologischen Prozeß des Yukatekischen, der vor vokalisch anlautenden Wörtern in Abhängigkeit von der Kategorie des vorangehenden Personalklitikums einen der Halbvokale /j/ oder /w/ einfügt. /j/ wird nur nach dem Klitikum der 3. Person eingeführt. Wenn nach dieser Prothese das Klitikum selbst unterdrückt wird, kann der Hörer aus dem Auftreten des Halbvokals schließen, daß er sich ein Klitikum der 3. Person dazudenken soll bzw. noch direkter, er kann /j/ als Zeichen der 3. Person reinterpretieren.
Auf allen sprachlichen Ebenen tritt folgendes Phänomen auf: Das Vorkommen oder die Unmöglichkeit einer bestimmten sprachlichen Einheit oder Eigenschaft X ist durch den Kontext, also durch Eigenschaften benachbarter oder umfassender sprachlicher Einheiten Y determiniert. Wenn Y präsent ist, ist X redundant, da es ja determiniert und also vorhersagbar ist. Wenn aber Y nicht Bestandteil der phonetischen Repräsentation ist - sei es, daß seine Kategorie dort grundsätzlich nicht repräsentiert ist, wie z.B. eine grammatische Grenze, sei es, daß es durch phonologische Prozesse getilgt wird, wie im Beispiel des yukatekischen Klitikums -, dann ist das Auftreten von X ein Indiz für Y. Konditionierte und insoweit funktionslose sprachliche Phänomene gewinnen distinktive und (im yukatekischen Beispiel) sogar signifikative Funktion, wenn die Kondition wegfällt. Das Prinzip ist in der Synchronie und, wie wir in Kap. 13 sahen, auch in der Diachronie wirksam.
Beschränkungen über das Auftreten phonologischer Einheiten im Rahmen größerer Einheiten geben dem Hörer positive oder negative Information über die Grenzen jener größeren Einheit, also insbesondere über grammatische Grenzen, die für das Verständnis wichtig sein können. Die strukturale Phonologie hat dann von der demarkativen Funktion phonologischer Einheiten gesprochen. Hier kam es darauf an zu zeigen, daß diese demarkative Funktion nur ein Spezialfall des allgemeineren Prinzips ist, daß konditionierte Phänomene Indizien ihrer Konditionen sind.
Mono- vs. bisegmentale Analyse
Auch die Frage der bi- vs. monosegmentalen Analyse von pränasalierten Obstruenten in Niger-Kongo-Sprachen (Swahili mtu “Mensch”) oder von Affrikaten in Sprachen wie dem Deutschen und Englischen ist eine Frage der Phonotaktik. Analysiert man [ts, tʃ, pf] bisegmental, so erhält man eine zusätzliche Klasse von initialen Konsonantengruppen, insbesondere in einer Sprache wie Englisch, die Folgen von Plosiv und Frikativ am Silbenanfang i.a. nicht zuläßt. Analysiert man sie monosegmental, erhält man eine zusätzliche Klasse von Segmenten, die ihrerseits nicht in dieselben Konsonantengruppen am Silbenanlaut eingehen wie die Plosive. D.h., das Kriterium, welches zur Entscheidung der Alternative zwischen mono- und bisegmentaler Analyse meist herangezogen wird - Vorkommen am Silbenanfang führt zu monosegmentaler Analyse -, ist nicht ganz stichhaltig.
Unter Gemination versteht man die Verdopplung eines Segments, normalerweise eines Konsonanten. Phonetisch handelt es sich einfach um die Dehnung des Segments, und insoweit wird das Phänomen im Kapitel über Prosodie behandelt. Phonologisch freilich können Langvokale und Langkonsonanten im Prinzip bisegmental sein. Im Japanischen zählt eine Silbe mit Langvokal als zwei Moren. Auch in der lateinischen Metrik zählt eine offene Silbe mit Kurzvokal als einmorig, eine mit Langvokal als zweimorig. Doppelkonsonanten gehen häufig auf Sequenzen zweier verschiedener Konsonanten zurück, von denen einer assimiliert wurde, wie in lat. nocte → ital. notte ‘Nacht’. In all diesen Fällen ist es phonologisch gerechtfertigt, das phonetisch lange Segment phonologisch als geminiert zu analysieren.
Übungsaufgaben
- (1 P.) In welcher phonetischen Eigenschaft unterscheiden sich Segmente, die den Silbengipfel bilden, von solchen, die den Silbenrand bilden?
- (1 P.) Was ist eine geschlossene Silbe?
- (1 P.) In welchem der folgenden Wörter tritt eine homosyllabische Konsonantengruppe auf:
a. ☐ Betrag b. ☐ Berta c. ☐ Lackmus
- (1 P.) Nach einem allgemeinen Prinzip nimmt normalerweise die Sonorität vom Silbenrand bis zum Gipfel kontinuierlich zu. Geben Sie ein Beispiel eines implikativen Gesetzes über initiale Konsonantengruppen, das dieses Prinzip illustriert.
- (1 P.) Analysieren Sie das Prominenzgefälle und das Sonoritätsgefälle in bair. Buab.
- (1 P.) Warum ist /tavt/ kein mögliches deutsches Wort?
- (1 P.) Repräsentieren Sie engl. nitrate und nightrate phonetisch inkl. Silbengrenze.
- (2 P.) Geben Sie die Konstituenz der Silbe des Worts spreizt (natürlich in IPA notiert) an.
Lösung - (3 P.) Welche Prozesse finden statt, wenn dt. Lineal zweisilbig wird?
- (4 P.) Transkribieren Sie dt. Matte und ital. matte (“verrückte”). Was drückt die Orthographie mit der Doppelkonsonanzschreibung aus?
- (6 P.) Zur Distribution von [z] und [s] im Deutschen
- (7 P.) Lexikalische Lücken
- (7 P.) Deutsche Worttrennung
- (9 P.) Phonotaktische Beschränkungen
- (14 P.) Zum deutschen Glottisverschlußlaut
- (14 P.)Kombinationsbeschränkungen
-
Wörter wie Stein werden im Oberdeutschen [ʃtaɪn], im Niederdeutschen dagegen [staɪn] ausgesprochen.
- (12 P.) Stellen Sie fest, ob eine phonologische Regel oder eine phonotaktische Beschränkung im Spiel ist, und formulieren Sie diese.
1 Nach Clark & Yallop 1995:67 ist ein Diphthong ein Vokal mit zwei Vokalqualitäten, von denen keine dominiert. Vokale, denen ein Onglide vorangeht oder ein Offglide folgt, wie sie im Englischen vorkommen, wären danach keine Diphthonge.
2 ['ʔɛʁplɩç] und [ʔɛʁ'blɩç] unterscheiden sich natürlich auch im Akzent.
3 In Kap. 11 wurde vorgeführt, wie man einen Tetraphthongen weganalysiert.